本文最后更新于 1692 天前,其中的信息可能已经有所发展或是发生改变。
基础正则 Day2
[abc] [a] [] 只匹配一个字符
[root@localhost 2]# grep '[abc]' clc.txt
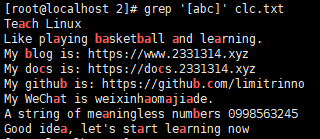
显示匹配过程 -o
[root@localhost 2]# grep -o '[abc]' clc.txt

可以匹配 [a-z] [A-Z] [0-9]
匹配大小写字母加数字
grep '[a-zA-Z0-9]'
简单写法 grep '[a-Z0-9]'
grep -i '[a-z0-9]' -i就是不区分大小写
[^abc] 取反排除为a b c 的字母
扩展正则
| 符号 | 含义 |
|---|---|
| + | |
| | | |
| () | |
| {} | |
| ? |
+ 前一个字符出现0或者0次以上
[root@localhost 2]# egrep '0+' clc.txt
My qq is 1250644268
My phone 131000022333
A string of meaningless numbers 0998563245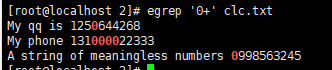
连续出现的数字
egrep '[0-9]+' clc.txt
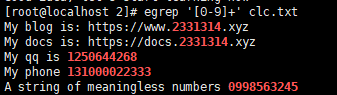
egrep -o 显示过程
[root@localhost 2]# egrep -o '[0-9]+' clc.txt
2331314
2331314
1250644268
131000022333
0998563245egrep -v 排除出现的数字
[root@localhost 2]# egrep -v '[0-9]+' clc.txt
Teach Linux
Like playing basketball and learning.
My github is: https://github.com/limitrinno
My WeChat is weixinhaomajiade.
Good idea, let's start learning now联系出现的字母
egrep '[a-Z]+' clc.txt
| 或者
egrep '[clc|cic]' clc.txt
[] 匹配一次或者一次以上
与|的区别就是|是一次性匹配
[] 是在括号内的字符按照单个匹配
() 是一个整体字符 或者反引用sed
均可匹配
[root@localhost 2]# egrep 'clc|cic' clc.txt
My name is clc not is cic
[root@localhost 2]# egrep 'c[li]c' clc.txt
My name is clc not is cic
[root@localhost 2]# egrep 'c(i|l)c' clc.txt
My name is clc not is cic{}
- 连续出现o{n,m}前一个字母o,至少连续出现n次,最多连续出现m次
- 连续出现o{n}前一个字母o,至少连续出现n次
- 连续出现o{n,}前一个字母o,最少连续出现n次
- 连续出现o{,m}前一个字母o,最多连续出现m次
?
good
god
goooodd
gd
[root@localhost 2]# egrep 'god|gd' good.txt
god
gd
[root@localhost 2]# egrep 'go?d' good.txt
god
gd